回帰分析、傾向スコア ... 介入グループと非介入グループの両方に似たような特徴を持つサンプルが含まれている状況を利用
この状況が成り立っていなさそうな時にDIDで対応できる。
不景気なので、A市の人全員にお金配りました。
せっかく配ったお金を全員が箪笥にしまって使わなかったら、配った甲斐が無いので、
配った事によってどれくらい多くお金使うようになったか知りたいです。
みたいな状況を考える。
配ったことの影響を見たいのだから、配った人と配って無い人を比較すれば良さそう。
比較対象の非介入グループとして、お金配ってない人を選ぶには、以下の2パターンが考えられる。
(が、どちらもバイアスが入るので後述するDIDをしましょうね。)
1.違う市B,C,Dの人を選ぶ
2.お金配り始める前のA市の人を選ぶ
1.違う市B,C,Dの人を選ぶ
Aの平均ととBの平均を比べたり、
Aの平均とB,C,Dの平均を比べることを考える。
バイアスを理解するために、極端な場合を考える。
Bがリッチな人が多く住む市で、毎月生活費1億円ですみたいな場合、この引き算の結果はマイナスになる。
これはお金配った結果がマイナスなのではなく、「A市とB市の固有の違い」と「お金配りの効果」を分けられていない、という状況。
つまりこの方法だと、「A市とB市の固有の違い」がバイアスとして乗ってしまう。
2.お金配り始める前のA市の人を選ぶ
7月にお金を配ったので、6月のAと8月のAの支出を比べることを考える。
この引き算の結果がお金配りの効果になりそうだが、お金を配らなかった去年のデータでこの引き算をしても、引き算の結果はプラスになってしまう。
なぜなら、8月はお盆があって旅行に行ったり、エアコンをつけるので光熱費が上がったりして、例年6月より支出が多いから。
このように時間を通したトレンドのバイアスが乗ってしまう。
DID実例

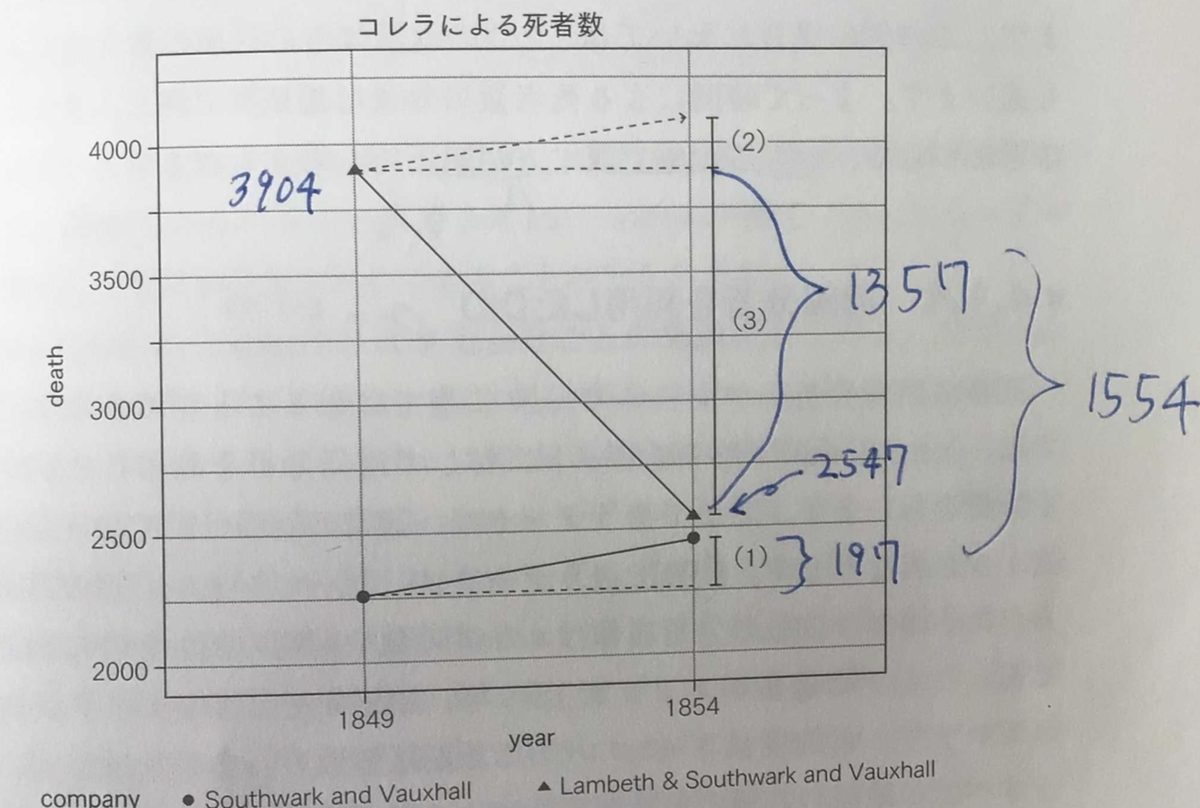
平行トレンドを実数で並行と捉えるのではなく、増加割合が並行と捉えた方が良い場合もあるらしい
上のケースだと、197人増えるはず、ではなく、8%増えるはず。
疑問
-1554を何かで割ると-39%????
回帰DID


上で1554を計算した式に当てはめると、β3が1554になってる
会社ごとにまとめないで、地域ごとに固定効果モデルっぽくもできる。

自己相関しているので、パラメータの有意差検定は優位になりやすい。よって普通の標準誤差ではなくクラスター標準誤差と呼ばれるものを使うべき
平行トレンド仮定
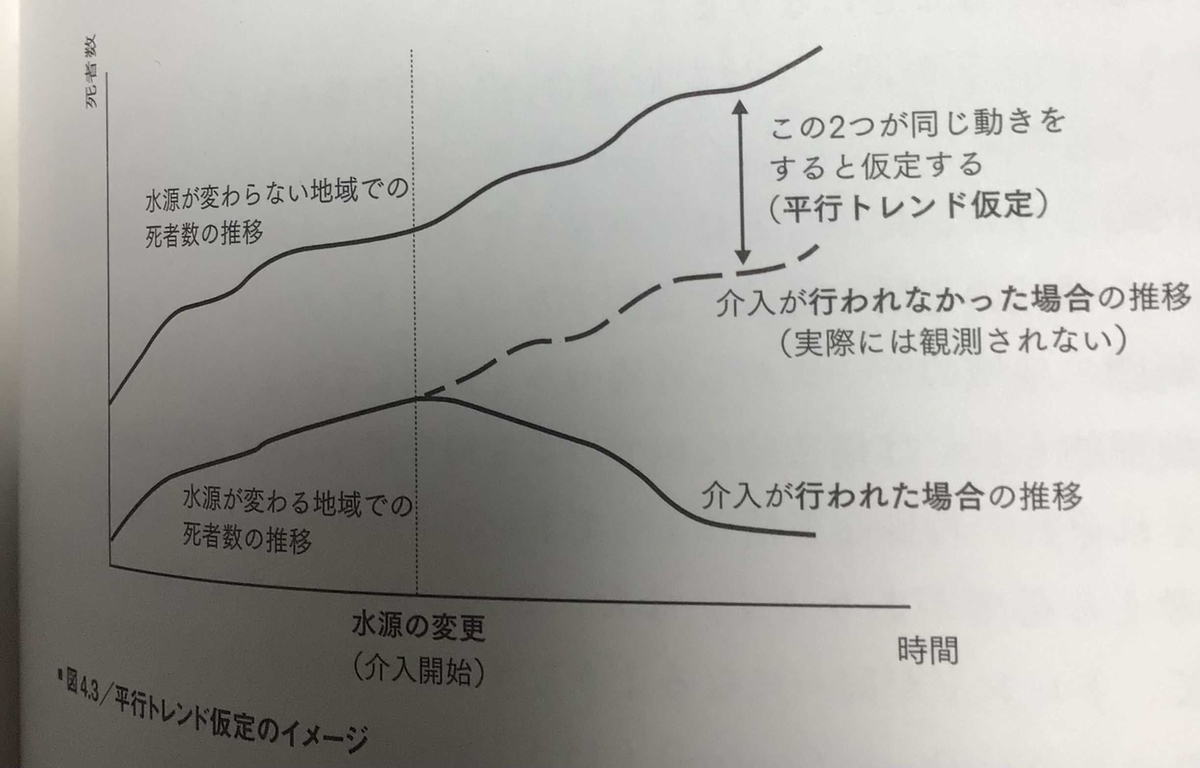
介入グループと非介入グループでトレンドが同じだという仮定
この仮定が成立しているかの確認はできない。(実際には観測されないから)
介入までの期間がある程度長く取れているのなら、介入までのトレンドを比較することで確認できるが、多くの場合明確な傾向を得ることはできない。
→平行トレンドが満たされるか、の判断は分析者がデータを生み出した地域や現象についてどう解釈しているかに依存する。
トレンドが同一で無い場合の対策
1.仮定を満たさないデータを取り除く
近いエリア同士だけで比較する
トレンドが近いエリアを抽出して比較(合成コントロール)
2.トレンドの乖離を説明する変数を加える
水源の例
水源の変化がなかった非介入群の街の一部に、浄水施設が設置されていた場合、平行トレンドが成り立たない。
施設が設置されたことを示す共変量を入れることで、施設の効果を取り除ける。(areaダミーと同じ)
DIDの欠点
1.複数の場所と時期でデータが必要
全ての地域に介入してたら使えない
2.どのデータを用いるかが分析者の仮説に依存
分析者は仮説を元に、平行トレンドが満たされていそうなデータを選んだり作ったり共変量で調整したりするが、本当にそれで満たされているかはわからないので、仮説に依存してしまう。
CausallImpact
DIDは結局「介入群が、もし介入されなかったらどうだったのか」を知りたいだけなのだから、それをモデルを使って予測すればいいのでは?
(図)
説明変数Xの選び方の注意点
Xも介入の影響を受けるような変数だとNG
介入→X増える→Yの予測値も増えてしまう
売上と強い相関があるが、介入の影響を受けない変数として、検索数があるのでGoogleTrendからとって使うと良い
タバコ抑制キャンペーンで各手法の確認
シンプルDID 結果:25箱

多時点DID
結果:20箱、対数にした場合は25%

平行トレンド成り立ってなさそうなのでDID使わない方がいいかも、、

CIでの予測
pointwiseは各時点での予測との差
結果:次第に強くなって、最終的に18

合成コントロールでの結果
トレンドが似ているエリアを抽出してm、それらのエリアの値から予測したものと比較
図はpointwiseに対応
結果:92年には15, 95年には20

DIDはやや強めに推定している
CIとSCMは似たような大きさに推定している。
掃除に複数の介入をおこなっていたら、判別できない
値下げと同時に広告も打ったら、どちらの効果かわからない。
並行トレンド仮定とは
成り立たない時の対策1,2
共変量を入れる
一通りなぞった後、
causal inpactの中身、ベイジアン構造時系列モデル
synthetic controlはどう合成するのか
自己相関とは
自己相関してるとなぜ困るのか
クラスター標準誤差